 |
|
FYI: I. D. in DNA 【文献】FACTS FOR FAITH, QUARTER 1-2002, ISSUE 8 《和訳》 細胞内の情報システムが「知的設計者」によって設計されたことの確 証 松崎英高(箱崎キリスト福音教会牧師)、テモシィ・ボイル(つくばクリスチャンセンター宣教師、物理学学士号、神学博士)共訳 南太平洋上に飛行機を飛ばせていたパイロットは、遠くに地図にはない島を発見 した。そして、もっと接近して観察するために、旋 回しつつ降下した。飛行機が降 下するにつれて、パイロットは島の海岸に配置された大きな岩を見つけ、一字ずつ字 を拾ってSOSと読ん だ。さらに、波が届かないところに、草で葺いた小屋を認めた。 躊躇せずに、パイロットは無線で救助を要請した。 このパイロットが取った行動は、合理的であっただろうか。そんなことは誰も問 題にもしないだろう。風と波の作用が、その海岸沿 いにあった岩で SOSというスペルをつづることなどあり得ないことを、彼は認識した[1]。意味が明瞭なメッセージは知性を持つ存在 に由来するに違いな いことを、彼は 経験的に知っていた。SOSは、英語の単語をつづってはいないが、万国共通の遭難信 号であるから、その意味が分る。その島の居住者は 、空からそれを見る 誰もがその意味を理解できることを知っていたので、"HELP"(助けて)という文字を 書かずに、海岸に特別な救助信号であるSOSをつづ った。 草で葺いた小屋もまた、パイロットが救助を要請するために無線連絡すべきだと 確信させる。それは、海岸の岩の配列が偶然の結果 ではなく、島に打ち 上げられた誰かの働きの結果であることのさらなる証拠となる。知的作業がなされた ことの付加的な証拠を伴う暗号化された情報は、そ れが存在することだけ に留まらず、それが設計されたものであることを支持する。その暗号を選択して採用 するには、知性を持つ行為者が必要である。そして 、暗号化された情報 は、何らかの意図を内包している。 科学者たちは、例のパイロットが救助要請のための無線通信をするきっかけと なったものと同じタイプの証拠を、過去40年に渡っ て細胞内に繰り返し 発見してきた。すなわち、彼らは、細胞の持つ生化学的な機構が情報に基づいたシス テムであることを発見してきた。しかも、細胞内の 化学的な情報は、暗号 化された情報として存在する。遺伝暗号(細胞の情報を暗号化するために使用される 法則)は、細胞の生化学的情報システムを特徴付け ている。 細胞内の暗号化された情報そのものが、知性を持つ設計者が存在することを支持 する強力な証拠である。さらに、例の島民の草で葺 いた小屋の場合のよ うに、最近の発見は、知性を持つ設計者が存在するという前提を確認する新たな証拠 を提供する。すなわち、遺伝暗号の起源を研究して いる分子生物学者たち は、それが知的設計によるものであることを支持する証拠に、予期せずして遭遇し た。それは、遺伝暗号を作成する法則が微調整されて いるというものであ る。これらの法則は、エラーを最小限にするという驚くべき機能を遺伝暗号に与え る。 遺伝暗号に生じるエラーを最小化するという特性は、細胞の生化学的な情報シス テムがミスを犯してもなお、高度に正確な複製によ り、重要な情報を伝 達することを可能にしている。それは、島に辿り着いた遭難者が岩をSSOとかOS Sと配列しても、救助の要請を知らせることができ るようなものである。 生化学的情報 蛋白質例の遭難者のメッセージが岩で書かれたように、細胞内の情報の記述は蛋白質の 合成によって始められる。生命の"馬車馬"分子であ る蛋白質は、細胞 内外の全ての構造や営みにおいて、本質的な役割を担っている。それらは細胞内や細 胞の周囲に位置する細胞間質において、構造を形成 する手助けをしてい る。他の役割として、蛋白質は化学反応を触媒したり、化学的なエネルギーを獲得し たり、細胞の防御系の働きをしたり、分子の保存や 輸送をしたりする[2]。 ポリペプチドと呼ばれる分子が蛋白質を作り上げる。一種類または複数の種類の ポリペプチドが結合して、蛋白質が生成する。ポリ ペプチドは精密な三 次元構造に折り込まれた鎖状の分子である。ポリペプチドの三次元構造は、一つのポ リペプチドが他のポリペプチドと相互作用して蛋白 質を形成する方法を決 定する。従って、ポリペプチドの構造がその機能を決定する[3]。 細胞内のメカニズムがアミノ酸と呼ばれるより小さな構成要素を(先頭から末尾 に向かって)互いに連結させることによって、ポリ ペプチドが生成する[4]。細胞はポリペプチドを作るために、20種のアミノ酸を使用する。細胞のポリペ プチド鎖を組み立てるアミノ酸には、いろいろな化 学的、及び物理的 な性質がある[5]。原理的には、20種のアミノ酸は、それらの可能な組み合わせと配 列のいずれにおいても結合して、ポリペプチドを生 成することができ る。 各々のアミノ酸の配列は、そのポリペプチド鎖に特有な化学的及び物理的な特徴 をポリペプチドに与える。その化学的及び物理的な 側面は、ポリペプチ ド鎖がどのように折りたたまれるのか、また、その結果、どのように他のポリペプチ ド鎖と相互作用をして機能的蛋白質を生成するかを 決定する。構造がポリ ペプチドの機能を決定するので、アミノ酸の配列が最終的にポリペプチドの果たす働 きのタイプを規定する。 ポリペプチドのアミノ酸配列は、情報を含んでいる。アルファベットの文字が単 語を作るように、互いに繋がったアミノ酸は細胞の 単語であるポリペプ チドを作る[6]。言語の場合、文字のある組み合わせが意味を持つ単語を作るが、他 の組み合わせは訳の分からないものとなる。アミノ 酸の配列もまた同様 である。あるものは機能的なポリペプチドを生成するが、他のものは細胞内で何の機 能も持たない無意味なポリペプチドを生成する[7]。 アミノ酸配列を情報として取り扱うことは、蛋白質の起源を理解しようとする研 究者にとって実りあるアプローチである[8]。さらに 、それは、研究 者たちが異なるアミノ酸配列の機能的な有用性を特徴づけることを助けてきた(表 1)。 DNA ポリペプチドと同様に、DNAは情報を含んでいる。事実、DNAの主要な機能は、情 報の貯蔵である。蛋白質と同様に、DNAはポリヌクレオチドと呼ばれる鎖状の分子から成っている[9]。二本のポリヌクレオチドの鎖が反平行に整列し て、DNA分 子を形成する。(一つの鎖の先端が他の鎖の末端と隣接するように、二本の鎖は互い に平行に配列されている。)二本一組のポリヌクレ オチド鎖は、互いの周 りにねじれており、よく知られているようにDNA二重らせんを形成している。細胞の メカニズムは、ヌクレオチドと呼ばれる4種の異なる 構成要素を互いに 連結させることにより、ポリヌクレオチド鎖を生成する。DNA鎖を作るために使用さ れる4種のヌクレオチドとは、それぞれ、A、G、C、T としてよく知 られているアデノシン、グアノシン、シチジン、チミジンである。 DNAは、細胞によって使用される全てのポリペプチドを作るために必要な情報を貯 蔵する。DNA鎖の中にあるヌクレオチドの配列がポ リペプチド鎖 中のアミノ酸の配列を特定する。(ポリペプチドを作るために)DNAの鎖に沿ってそ れぞれのアミノ酸に対応して暗号化されたヌクレオ チドの配列を、科学 者たちは遺伝子と呼ぶ[10]。遺伝子を使用することによって、DNAはポリペプチド鎖 のアミノ酸配列の中に機能的に表現される情報を貯 蔵する。DNA 鎖のヌクレオチドはアルファベットの文字として、また遺伝子は単語として機能する (表1)。 表1
分子生物学のセントラルドグマ(中心的教義)"分子生物学のセントラルドグマ"として知られる細胞内の情報の"流れ"を考慮し ないでは、生化学的情報系の議論は完全とは言えな い[11]。 この概念は、DNAに貯 蔵された情報が、アミノ酸の配列とポリペプチド鎖の活性を通して、どのようにして 機能的に表現される ようになるかを描写する。 複雑な細胞の核の内部にあるDNAは、図書館で見出される参考図書に相当する。そ のような本は図書館から持ち出しが禁じられている が、そこに貯蔵されている情報 を複写することはできる。同様に、DNAはボリペプチド鎖の合成を指揮するために、 核を離れるわけでは ない。むしろ、細胞のメカニズムは、もう一つのポリヌクレオ チドであるメッセンジャーRNA(mRNA)を組み合わせることによって、遺 伝子の配列 を複製する[12]。この単一の鎖状の分子は、構造においてDNAと似てはいるが、同一 のものではない。DNAとmRNAとの最も重要 な違いの一つは、mRNA鎖を生成するため に、チミジンの代わりにウリジン(U)が使用されていることである。科学者たち は、DNAから mRNAを複製する過程を転写と呼んでいる。 一旦組み立てられると、mRNAは細胞内の核から細胞質に移動する。リボゾーム で、mRNAはポリペプチド鎖の合成を指揮する[13]。ポ リヌクレオチドの配列という 情報の内容は、ポリペプチドを構成するアミノ酸の配列に翻訳される。それは、日本 語を英語に翻訳するこ とによく似ている。 生化学的なシステムにおける情報の流れを描写するための類比として使用される 言語は、決して偶然などではない。生化学的なシス テムは情報システムなのであ る。 遺伝暗号 暗号化された生命の情報DNA内のヌクレオチドの配列が、どのようにしてポリペプチド内のアミノ酸配列に 翻訳されるのだろうかと不思議に思う人がいるかも 知れない。細 胞内の情報の貯蔵とその機能的表現の間には、一種のギャップがあるように見える。 DNAの4つの異なるヌクレオチドとポリペプチドを組 み立てるために使 用される20種のアミノ酸の間に、1対1の関係があるわけではない。細胞は、20種のア ミノ酸を特定するために3つのヌクレオチドを一組 とする暗号を使 用することによって、このギャップを克服している[14]。 細胞は、これら三つのヌクレオチドの配列でポリペプチドを構成する20種のアミ ノ酸を指定する法則を使用する。分子生物学者たち は、この法則を遺 伝暗号と呼んでいる。三つで一組のヌクレオチドは"コドン"と呼ばれ、遺伝暗号の基 本的な伝達単位に相当する。遭難した島の居住者が 彼の窮状を伝えるた めにSOSという三つの文字を使用したのと同じ方法で、一つのアミノ酸を指定するた めに、遺伝暗号は三つのヌクレオチドからなる"文字 "を使用する。こ の遺伝暗号は、全ての現存する生物において本質的に共通である。 64個(訳注:4×4×4)のコドンが遺伝暗号を作り上げる。遺伝暗号は20種のアミ ノ酸のみを暗号化する必要があるので、遺伝暗号の 幾つかは 余分なものである。すなわち、異なるコドンが同じアミノ酸のために暗号化されてい る。場合によっては、一つのアミノ酸が6個までの 複数の異なるコドンに よって特定されることもある。また、他のアミノ酸はたった一つのコドンによって特 定されることもある(表2)。 興味深いことに、終止コドンとか"ナンセンスコドン"と呼ばれる幾つかのコドン は、どのアミノ酸をも指定しない。(例えば、UGAは 終止コドン である。)これらのコドンは、常に遺伝子の終端に現われ、ポリペプチド鎖の末端が どこなのかを細胞に知らせる。終止コドンは、細胞 の情報システムのため に"句読点を施す"という働きをする。 あるコドンは、遺伝暗号としては二重の役割を演じる。これらのコドンは開始コ ドンと呼ばれ、アミノ酸を暗号化するのみではなく 、ポリペプチドがど こで始まるかを細胞に"教える"こともする。例えば、5’GUGはアミノ酸であるバリン を暗号化するのみでなく、ポリペブチド鎖の開始点 を特定する。開 始コドンは細胞の情報システムのために、"大文字にする"(訳注:すなわち、文章の 最初であること)という類の機能を持っている。( 訳注:従って、すべ ての遺伝子はGUGまたAUGで始まり、UAA、UAG、またUGAで終わる。) 表2 遺伝暗号
表2は普遍的遺伝暗号(訳注:全ての生物が利用する遺伝暗号)を表している。 これに従って、細胞のメカニズムにより、DNAのヌク レオチド配列の 中に貯蔵されている情報は、ポリペプチドを構成するアミノ酸の配列の中に機能的に 発現される情報に転換される。遺伝暗号の基本的な 単位は"コドン"と呼 ばれ、三つのヌクレオチドの配列からなる。このコドンは64種あり、それぞれがポリ ペプチドを作るために細胞が利用する20種のアミ ノ酸に対応してい る。場合によって、同じアミノ酸が幾つかの異なるコドンに対応しているので、それ らは重複することになる。また、ポリペプチド配列 の始まりと終わりを特 定する"開始コドン"と"終止コドン"もある。表2は、DNAに貯蔵されている情報が mRNA分子に転写された時に生成されるコドンを表して いる。コド ンの最初のヌクレオチドは"5'末端"と呼ばれる。表2では、コドンの最初のヌクレオ チドである5'末端は、表の左端にある最初の列にあ る。そして、2 番目のヌクレオチドは、表の最上段の行にある。"3'末端"と呼ばれているコドンの3 番目の位置(訳注:コドンの最後のヌクレオチド)は 、それぞれのコ ドンの右端にある。例えば、表2において、左上方に書いてある5'UUUと5'UUCという 二つのコドンはフェニルアラニン (phenylalanine)というアミノ酸を特定する。そのアミノ酸はPheと略されている。 遺伝暗号と知的な設計島で観測された情報が、知性を持つ行為者がある目的をもってそれを描いたもの であると、そのバイロットが判断するのは理にかな っている。生命の 最も基本的な構造とプロセスを究極的に規定する分子であるDNAや蛋白質の情報の内 容によって、自らの意図を心に抱く、知性を持つ設 計者が生命の原因で あるとの結論に導かれるのは、避けられないことである。この結論は、海岸のメッ セージを見つけて、無線で助けを求めた時のあのパイ ロットの判断と同程度 に合理的なものである。 遺伝暗号、すなわち、DNAにある貯蔵された情報を蛋白質という機能的な情報に翻 訳する一連の規則は、知性を持つ設計者の存在をさ らに支持する。 すべての暗号には、その暗号を規定する一連の規則を造り上げるために、知性を持つ 行為者を必要とする。 すべての生命に共通した遺伝暗号を規定する一連の規則には、生命が設計された ことを支持するさらに驚くような証拠がある。細胞 が情報を使用した り、ある世代から次の世代に情報を伝達したりする時に、遺伝暗号は自然に起こるエ ラーを防ぐために、心を奪われるほどに魅力的な能 力を発揮する。暗号を 定性的(質的)に分析すると、その微調整のあり方は部分的にのみ明らかになる。と ころが、遺伝暗号においてエラーを最小化する特性 を定量化する方法を採 用した最新の研究は、知的な設計が存在することを支持する新たなこの証拠を、はっ きりと見えるようにする。 突然変異遺伝暗号のエラーを最小化する能力が、知的な設計が存在することを支持するそ れほどに強力な指標となるのは、なぜだろうか。DNA の貯蔵された情 報を蛋白質という機能的な情報に翻訳することが、遺伝暗号の主な機能である。遺伝 暗号の伝達や翻訳の失敗が高い頻度で起こることは 、細胞に対して破壊的 となり得る。突然変異が細胞にどれほどの影響を与えるかを少しでも考えることは、 理解の助けになる。 突然変異とは、DNAのヌクレオチドの配列に起こる変化のことである[15]。DNAは いくつかの異なるタイプの突然変異を被る。塩基置 換変異 は、通常見られるタイプである。塩基置換変異においては、DNA鎖における一つかそ れ以上のヌクレオチドが別のヌクレオチドに置き換 えられる。例えば、 AはGに、またCはTに置き換えられることがある。このような置換は、置き換えられた ヌクレオチドがその一部となっていたコドンを変え る。そのコドンに よって特定されるアミノ酸が変化することにより、そのポリペプチド鎖の化学的、お よび物理的側面の変化が起こる。もし、置き換えら れたアミノ酸が本来の アミノ酸とは著しく異なる物理化学的性質を持つようになれば、そのポリペプチドは 不適当に折りたたまれることになる。この不適当な 折りたたみがポリペプ チドに影響を与えて、機能が減退するか、あるいは機能を失った蛋白質を生じること になる。ほとんどの突然変異は、蛋白質の構造と機 能に対して有意でしか もマイナスに影響するので、細胞の健康を害する。 設計されたことの定性的(質的)な証拠遺伝暗号の冗長性(訳注:20種のアミノ酸を特定するのに、4×4×4=64通りのコ ドンが使用される。)は、偶然であるというよりも 、よく工夫 されてのことのように思える。遺伝暗号の規則は、細胞が塩基置換変異の有害な影響 を避けるための設計を組み込んでいる。例えば、6 個のコドンがロイシン (Leu)というアミノ酸に対応している。ポリペプチドにおける特定のアミノ酸の位 置で、もしLeuが5’CUU(5’はコドンの開始を指す 記号)に対 応しているなら、3’の位置(訳注:3’とはコドンの最後の記号)でUがC, A,またGに置き換わる塩基置換変異は新しい3つのコドンである5’CUC、5’CUA、5’ CUGを生じる。しかし、そのすべてもまたLeuに対応 す る(表2)。全体としての影響は、ポリペプチドのアミノ酸配列に変化を生じさせな い。このシナリオによって、細胞は塩基置換変異の 有害な影響を首尾よく 避けるのである。 同様に5’の位置のCがUに変化すると、新しいコドンである5’UUUを生じる。それ は、物理的にも化学的にもLeuと類似した性質を持 ったアミ ノ酸であるフェニルアラニンを指定している。CがAかGに変化することは、それぞ れ、イソロイシンとバリンに対応するコドンを生じる 。これら二つのアミ ノ酸も、ロイシンと類似した化学的、物理的な性質を有している。定性的(質的)な 意味で、遺伝暗号は、塩基置換変異に原因するエラ ーを最小化するように 組み立てられているように思える。 設計されたことの定量的(量的)な証拠最近、バース大学(イギリス)とプリンストン大学の科学者たちは、遺伝暗号の エラーを最小化する能力を定量化することを目指し て研究した。初期 の研究では、塩基置換変異の有害な影響に対する自然界に存在する遺伝暗号の耐性が 見積もられた。それによると、普遍的遺伝暗号(訳 注:すべての生物に共 通な遺伝暗号の専門用語)の耐性は、それとは異なるコドンを無作為に割り当てるこ とによって生じる遺伝暗号が被る被害の約0.02%( 5000分の1) 以下であることが指摘された[16]。 この初期の研究では、自然界ではある種の塩基置換変異が他の塩基置換変異より も多くの頻度で起こることが見落されている。例え ば、AからGへの 置換は、AからC、あるいは、AからTへの突然変異よりも高い頻度で起こる。研究者た ちが彼らの解析にこの修正を取り入れたところ、自 然界に存在する遺 伝暗号は、無作為に生じた100万組以上もの遺伝暗号よりも優れた耐性を持っている ことを、彼らは発見した。さらに、彼らは、そのエ ラーを最小化する能 力に関して、自然界の遺伝暗号が、すべての可能な遺伝暗号の中で最適なものに近い ことを発見した[17]。自然の普遍的遺伝暗号は、 100万組の無作為 で生じる遺伝暗号の中で、真に唯一の優れたもの、あるいはそれ以上のものなのである。 遺伝暗号がエラーを最小化するという特性は、実際には以上の結果が指摘するよ りもさらに劇的なものである。研究者たちは、無作 為に生じる100 万組の遺伝暗号においてエラーを最小化する能力を計算した。すると、それらのエ ラーを最小化する能力の指数はある分布を持つが、自 然界に存在する遺伝暗 号の能力はその分布の外側にあることを、彼らは発見した[18]。研究者たちは、普遍 的遺伝暗号と同様なタイプのもので、同程度の余剰 な暗号を持つ 1018組の可能な遺伝暗号が存在することを見込んでいる。これらの暗号はすべて、エ ラー最小化分布の内側にある。この発見は、1018組 の可能な遺伝 暗号のうち、たとえあるとしてもわずかなものだけが、自然界に共通に見出される遺 伝暗号に近いエラーを最小化する能力を持っている ことを意味している。 この結果の受け入れ難い哲学的な意味を心配する故に、ある研究者たちは遺伝暗 号の最適性を疑ってきた[19]。しかし、バース、プ リンストンな どの研究チームはこれらの疑問に効果的に答えたのであった[20]。 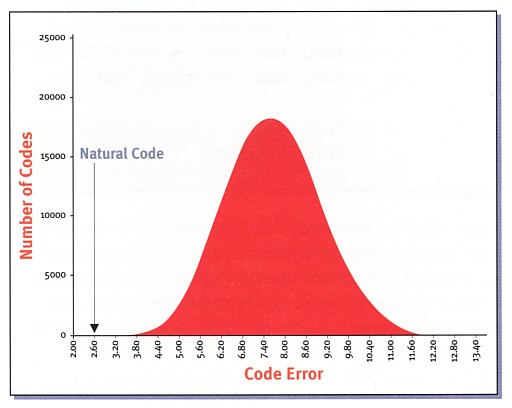 この図表は自然界の遺伝暗号と無作為につくられた暗号を比較するものである。 下の数字はエラーの頻度を表し、ほとんどの場合 8.00前後の数値と なる。"Natural code"と書いてある実際の遺伝暗号はたったの2.60で他の可能な暗号より遥かに優れ ている。自然の遺伝暗号は突然変異によるエラーを 最小限に食い 止める優れた特質を持つ。 遺伝暗号の背後にある力彼らの研究結果に基づいて、バースとプリンストンの科学者たちは、遺伝暗号の 法則が偶然の出来事により存在するようになったこ とはあり得ないと 結論した。ランダムな生化学的な反応により組み立てられた遺伝暗号が、ほぼ理想的 なエラーを最小化する能力を持つことはないだろう 。これらの研究者たち は、ある"力"が遺伝暗号を形作ったと論じている。しかし、彼らは遺伝暗号の起源を 超自然的に説明するのではなく、自然選択に任せて いる。彼らは、"自 然選択力"に作用された偶然の出来事が何度でも繰り返されて、遺伝暗号のエラーを 最小化する能力を生じさせたのだと信じている[21]。 遺伝暗号は進化できるか遺伝暗号が進化したことの蓋然性を問う他の科学的研究がなされた。1968年に、 ノーベル賞受賞者であるフランシス・クリックは、 よく知られた 第1級の論文において、遺伝暗号は有意な進化を受けなかっただろうと、確信をもっ て論じた[22]。クリックの立場の論理的根拠は、容 易に理解できる。 コドンの割り当てのどのような変化も、細胞内で作られるあらゆるポリペプチド内の アミノ酸に変化をもたらす。ポリペプチド(のアミ ノ酸配列)におけるこ のような大規模な変化は、大量の欠陥蛋白質を生じるに至ることであろう。遺伝暗号 における考えられる限りのほとんどどのような変化 も、細胞にとっては致 死的となるだろう。 遺伝暗号が長い時間に渡って徐々に変化して、エラーを最小化する能力を最大に する1組の規則が生じたとしても、この過程が起こ るための時間は十分 なのだろうか。生物物理学者のヒュバート・ヤッキーは、この問題を取り上げた[23]。彼は、自然界に見られる普遍的遺伝暗号に行き当 たるためには、自 然選択は1.40×1070の異なる遺伝暗号を調査しなければならないことを算出した。 ヤッキーは、その暗号が創作されるために使用できる 最大時間を 6.3×1015秒(訳注:約2億年)と見積もった。単純に計算して、自然選択には普遍 的遺伝暗号を見出すための十分な時間が欠けている 。それは、1秒 間に約1054組の暗号を評価し続けなければならないことになるからだ。 他の研究者は、遺伝暗号の起源は生命の起源と一致することを示唆した。進化論 的なパラダイム内で結果が出されたものであるが、 有名な生命の起源 の研究者であるマンフレッド・アイゲンは遺伝暗号の年齢を38±6億年と見積もった[24]。最近の地球化学的な証拠は、地球上の生命が 最初に出現した のは38.6億年前としている[25]。 遺伝暗号の超自然的起源DNAの中に貯蔵されている情報をポリペプチドによって使用される情報に翻訳する ために細胞が使用する一連の規則である遺伝暗号は 、突然変異に よって引き起こされるエラーに抵抗する能力に関して、真にユニークな最適性を持っ ている。遺伝暗号は、それが無作為の生化学的な反 応によって生じた偶然 な結果であるという説明をも、あるいは自然選択という盲目的な力に導かれた進化の 過程の結果であるという説明をも、断じて拒絶する 。遺伝暗号の進化は、 細胞にとっては破滅的なものとなるだろう。生命の誕生が急速に起こったことを考え ると、自然選択が自然界に見られるよく設計された 普遍的遺伝暗号に偶然 に出くわすには、時間が余りにも短い。遺伝暗号は、地球上に生命が最初に現われた 時に生じたように思える。このような証拠の全てが 、遺伝暗号の原因は知 性を持つ設計者であるという結論に導く。 暗号化された情報は、それを生じさせるだけでなく、その暗号を構成する一連の 規則を設計して適用するためにも、知性を持つ行為 者が必要である。 このことを考慮する時に、遺伝暗号の原因が知性を持つ設計者であるという、この結 論はさらに説得力のあるものとなる。遺伝暗号の驚 くべき微調整は、聖書 と合致して、知性を持つ設計者が存在することを支持する、論理的に一貫した補強的 な証拠となる。海岸にあった岩で書かれたSOSと草 で葺いた小屋と同様 に、遺伝暗号は、創造者が熟慮しつつ意図的にそのメッセージを書いたことを示す指 標なのである。 付録 非普遍的遺伝暗号はどうなのかバース大学とプリンストン大学の科学者たちは、フランシス・クリックの研究を 十分に認めた上で、"非普遍的遺伝暗号"が存在する が故に、遺伝暗 号の最適な設計を説明するために、なおも進化に頼っている。自然界に存在する遺伝 暗号は一般には共通であると見なされている。一方 で、幾つかの"非普遍 的遺伝暗号"が存在する。それは、コドンの若干修飾された割り当てを採用した遺伝 暗号である。恐らく、これらの"非普遍的遺伝暗号" は一般的な普遍的遺 伝暗号から進化したものである。したがって、研究者たちは遺伝暗号の進化は可能で あると議論する。しかしながら、"非普遍的遺伝暗 号"のコドン割り当て は、一つか二つのコドン割り当てのみが異なっていることを除いて、大部分において 普遍的遺伝暗号と一致している。"非普遍的遺伝暗 号"は、普遍的遺伝暗 号の異常と見なす方が良い。 "非普遍的遺伝暗号"の存在は、遺伝暗号の大規模な進化があり得ることを示唆し ているのだろうか。答えはノーである。慎重な研究 は、"非普遍的 遺伝暗号"におけるコドンの変化は、常にミトコンドリアのような比較的小さなゲノ ムで起こることを明らかにする。そして、(1)その特 別なゲノムの中で 低い頻度で生じるコドン、あるいは(2)終止コドンのどちらかを含む。これらのコド ンの割り当てにおける変化は、致死的なシナリオを ならずに起こり得 る。というのは、細胞や微小器官の中にあるほんのわずかな数のポリペブチドだけ が、アミノ酸配列の変化を受けるだろうから。そうい うわけで、遺伝暗号の 限られた進化が起こりうるが、それは特別な環境の中でのみなのである[26]。 Footnotes1 Peter Kreeft, Fundamentals of the Faith: Essays in Christian Apologetics(San Francisco: Ignatius Press, 1988), 25-26 2Robert C. Bohinski, Modern Concepts in Biochemistry, 4th ed. (Boston: Allyn and Bacon, 1983), 86-87 3 Harvey Lodish et al., Molecular Cell Biology. 4th ed. (New York: W.H. Freeman, 2000), 54-60 6 Michael Denton, Evolution: A Theory in Crisis(Bethesda, MD: Adler & Adler, 1986), 308-25; Walter L. Bradley and Charles B. Thaxton,“Information and the Origin of Life,”in The Creation Hypothesis; Scientific Evidence for an Intelligent Designer, ed. J.P. Moreland (Downers Grove, IL: InterVaristy Press, 1994), 188-90 8 Hubert P. Yockey, Information Theory and Molecular Biology(Cambridge: Cambridge University Press, 1992); Charles B. Thaxton, Walter L. Bradley, and Roger L. Olsen, The Mystery of Life’s Origin: Reassessing Current Theories(Dallas: Lewis and Stanley, 1994), 127-43; Bernd-Olaf Kuppers, Information and the Origin of Life, (Cambridge, MA: The MIT Press, 1990). 10 遺伝子の構造は、ここで描写されたものよりもずっと複雑である。生化学や分子生物学のどの教科書でも、遺伝子の構 造のもっと完全な議論のための参考となり得る。 11David Freifelder, Molecular Biology, 2d ed. (Boston, MA: Jones and Bartlett Publishers, 1987), 208. 15 Lubert Stryer, Biochemistry, 3d ed. (New York: W. H. Freeman, 1988), 675-76. 16 David Haig and Laurence D. Hurst,“A Quantitative Measure of Error Minimization in the Genetic Code,”Journal of Molecular Evolution33 (1991): 412-17. 17 Gretchen Vogel,“Tracking the History of the Genetic Code,”Science281 (1998), 329-31; Stephen J. Freeland and Laurence D. Hurst,“The Genetic Code is One in a Million,”Journal of Molecular Evolution47 (1998): 238-48; Stephen J. Freeland et al.,“Early Fixation of an Optimal Genetic Code,”Molecular Biology and Evolution17 (2000): 511-18. 18 Freeland and Hurst, 238-48. 19 Massimo D. Giulio,“The Origin of the Genetic Code,”Trends in Biochemical Sciences 25 (2000): 44. 20 Stephen J. Freeland, Robin D. Knight and Landweber,“Measuring Adaptation within the Genetic Code,”Trends in Biochemical Sciences25 (2000): 44; Stephen J. Freeland and Laurence D. Hurst,“Load Minimization of the Genetic Code: History Does Not Explain the Pattern,”Proceedings of the Royal Society of London B265 (1998): 2111-19; Terres A. Ronneberg, Laura F. Landweber and Stephan J. Freeland,“Testing a Biosynthetic Theory of the Genetic Code: Fact or Artifact?”Proceedings of the National Academy of Sciences, USA97 (2000): 13690-95; Ramin Amirnovin,“An Analysis of the Metabolic Theory of the Origin of the Genetic Code,”Journal of Molecular Evolution44 (1997): 473-76. 21 Robin D. Knight, Stephen J. Freeman and Laura F. Landweber,“Selection, History and Chemistry: The Three Faces of the Genetic Code,”Trends in Biochemical Sciences 24 (1999): 241-47. 22 ]F. H. C. Crick,“The Origin the Genetic Code,”Journal of Molecular Biology 38 (1968): 367-79. 24 Manfred Eigen et al.,“Hoe Old is the Genetic Code? Statistical Geometry of tRNA Provides an Answer,”Science 244 (1989), 673-79. 25 Fazale Rana,“Origin-of-Life Predictions Face Off: Evolution vs. Biblical Creation,”Facts for Faith 6 (Q2 2001), 41-47. 26 Shozo Osawa et al.,“Evolution of the Mitochondrial Genetic Code I. Origin of AGR Serine and Stop Codons in Metazoan Mitochondria,”Journal of Molecular Evolution29 (1989): 202-7; Dennis W. Schultz and Michael Yarus,“On the Malleability in the Genetic Code,”Journal of Molecular Evolution42 (1996): 597-601; Eors Szathmary,“Codon Swapping as a Possible Evolutionary Mechanism,”Journal of Molecular Evolution32 (1991): 178-82. |